Transformer 到底怎么生成文本:逐层拆解
Transformer 到底怎么生成文本:逐层拆解
一句话:Transformer 推理就四个阶段——Attention(信息路由)→ FFN(知识存储)→ 层层堆叠(抽象升级)→ 解码(从向量到词)。一旦你把这四个阶段吃透,KV Cache 为什么吃内存、长上下文为什么贵、temperature 到底在调什么、模型为什么会产生幻觉、speculative decoding 怎么加速——这些工程决策突然就变得自然而然了。
阶段一:Attention——让每个 token “看到”其他所有 token
一个 token 刚进入 Transformer 层的时候,它对周围的 token 一无所知。Attention 就是来解决这个问题的。
每个 token 通过三个学出来的权重矩阵做投影,产出三个向量:
- Q(Query,查询): “我现在需要什么信息?”——当前 token 对历史的检索请求
- K(Key,键): “我这里有什么信息可查。”——每个 token 的索引条目
- V(Value,值): “这就是具体内容。”——被”关注”时实际传递出去的信息
当前 token 的 Q 去跟每个前置 token 的 K 做点积,得到一组原始注意力分数。缩放、过 softmax 变成概率分布,然后用这个分布对所有 V 做加权求和。结果是一个向量——它代表当前 token 以前面所有内容为条件的表示。
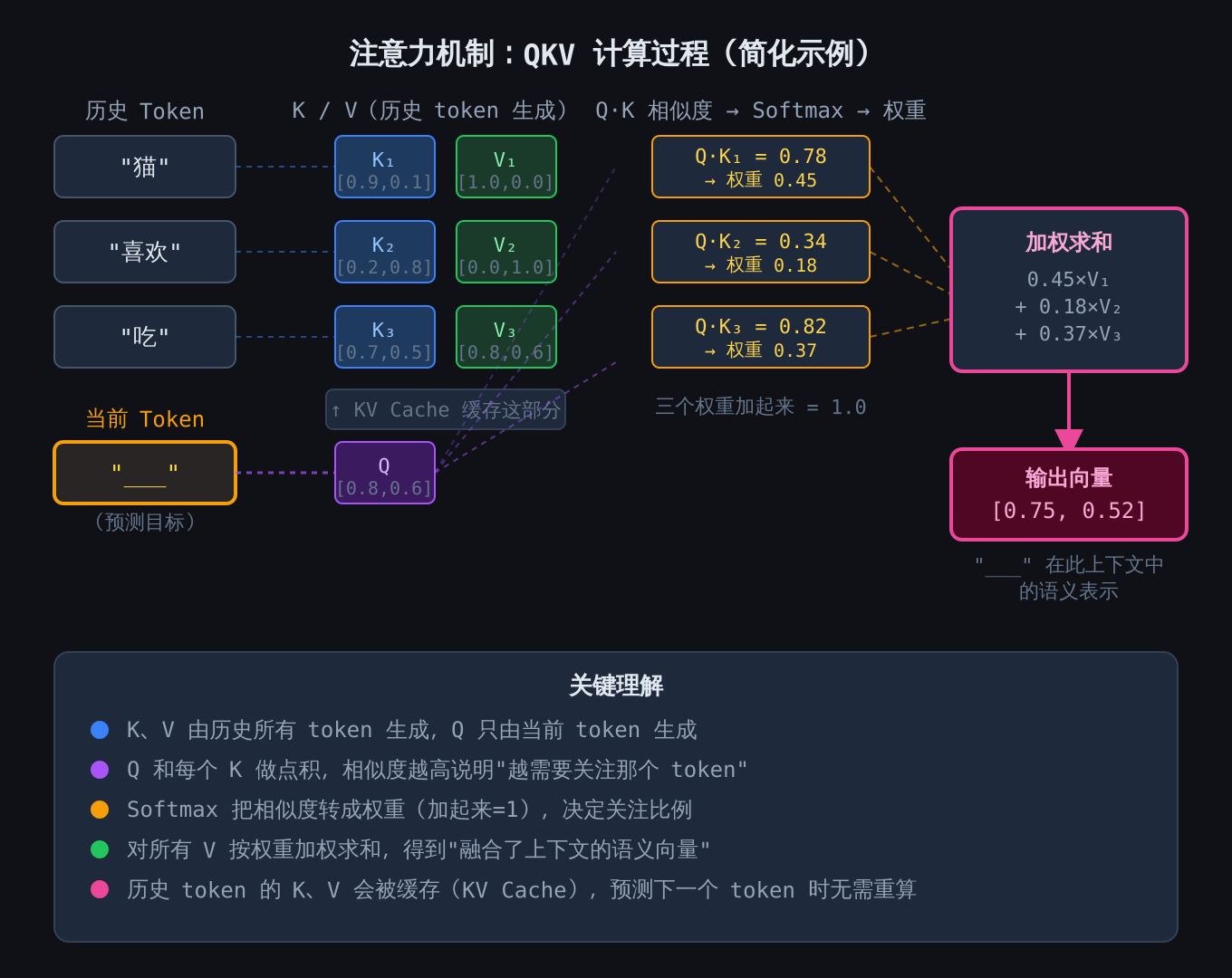
KV Cache 是让这一切能实际运行的命门。 自回归生成是一个一个 token 往外吐的。如果没有缓存,每一步都要把前面所有 token 的 K 和 V 重新算一遍——纯纯的 O(n²) 浪费。有了 KV Cache 就不一样了:一个 token 的 K、V 一旦算出来就存着。下一步只算最新 token 的 Q、K、V,历史的 K、V 直接从缓存里读。每一步从 O(n²) 变成 O(n)。这就是自回归生成能落地的全部原因。
阶段二:FFN(Feed-Forward Network)——知识存在这里
Attention 本质上是个加权平均——从根本上说是线性的。堆一层线性再堆一层线性,最终会坍缩成一个等效的线性变换。这模拟不了人类语言的复杂度。
FFN 打破了这种线性。
它拿 Attention 产出的向量(通常 768 到 4096 维,看模型大小),过一个两层变换:先扩展到 4 倍维度(比如 768 → 3072),上一道非线性激活(ReLU 或 GELU),再压回原来的维度。扩展给了模型一个高维空间去表示复杂的特征交互;激活函数把负值清零,确保两个线性层不会数学上坍缩为一个;压缩则映射回这一层标准的输出格式。
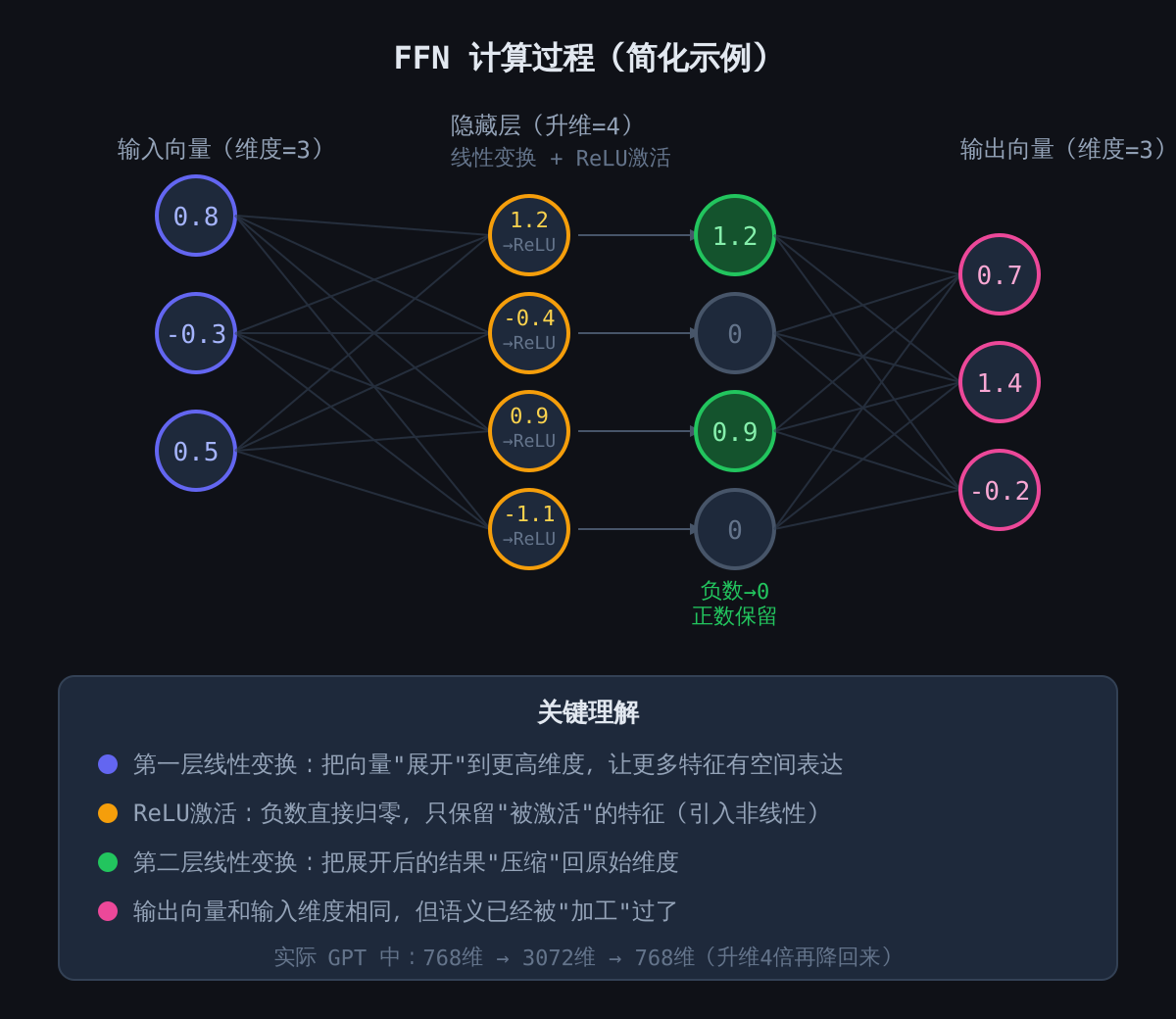
有一系列很值得关注的研究表明:模型大部分事实性知识存在 FFN 的权重里,而不是 Attention 的模式里。”巴黎是法国的首都”这个东西,活在 FFN 权重中,不在注意力分布里。Attention 负责路由信息,FFN 负责存储信息。这解释了为什么模型编辑技术(ROME、MEMIT 之类)瞄准的是 FFN 权重,也解释了为什么 FFN 大约占了 Transformer 参数量的三分之二。
阶段三:层层堆叠——从语法到推理
Attention + FFN = 一个 Transformer Block。现代模型堆了十几个(小蒸馏模型)到一百多个(前沿模型)这样的 Block。每个 Block 都有自己独立的三套 QKV 和 FFN 权重矩阵,上一个 Block 的输出就是下一个 Block 的输入。
这种堆叠创造了抽象的层次:
- 浅层学表面模式——语法、词性、局部词语关系
- 中层学语义结构
- 深层处理抽象推理、事实整合和长距离依赖
KV Cache 必须按层维护,这才是长上下文贵的真正原因。以 96 层、128K context window、128 维 KV 头为例:96 × 128K × 128 × 2(K+V)× 2 字节(FP16)——光缓存就要吃掉大约 6GB 显存。这就是为什么 GQA(Grouped Query Attention)、KV 量化和滑动窗口注意力这些东西不是”锦上添花的优化”,而是生产部署的硬门槛。
阶段四:解码——从向量变回词语
最后一个 Transformer Block 跑完,你手上是一个向量(比如 768 维),它在丰富的语义空间里代表最后一个 token。但你需要的是一个词。
输出向量乘以反嵌入矩阵(unembedding matrix)——通常是原始 token 嵌入矩阵的转置,这个叫 Weight Tying 的技巧能省一半参数量——产出 logits:词汇表里每个 token 的原始分数。对于 50,000 个 token 的词汇表,这就是 50,000 个数字,代表模型对每个可能的下一个词的未校准偏好。
Logits 过一道 softmax 变成正经的概率分布,然后采样策略决定实际选哪个 token:
- greedy decoding(temperature=0): 永远选概率最高的那个。确定、可复现,但通常无聊——产出容易重复、可预测
- Temperature 采样: 在 softmax 之前把 logits 除以一个温度值。高温(>1)把分布拉平,稀有 token 更可能被选中,输出更有创造性。低温(<1)让分布更尖锐,模型更保守
- Top-p(核)采样: 按概率排序,只保留累积概率超过 p(比如 0.9)的最小 token 集合,然后从这个截断集合里采样。模型确定时候选池小,模型不确定时候选池自动扩大

采样是推理过程中非确定性的唯一来源。 logits 本身是确定性的(同样的权重和输入,产出同样的 logits),是采样这一步引入了随机性。这也是幻觉的入口:如果模型把一个事实上错误的 token 赋予了不可忽略的概率,而采样器恰好选中了它——模型就会自信地输出虚假信息。架构本身没有任何事实核查机制;它只知道概率分布。
为什么这些对你干活有意义
四阶段管线一旦内化——Attention 通过 KV Cache 路由信息,FFN 存储知识,多层构建抽象,解码从概率分布采样——很多工程决策就会变成直觉:
- 你会立刻理解为什么长上下文场景必须做 KV Cache 压缩
- 你会明白 speculative decoding(用一个小草稿模型先快速提议 token,然后用完整模型一次前向传播验证)为什么能加速生成而不改变输出分布
- 你会领悟为什么微调 FFN 层可以在注入事实更新的同时保留风格和流畅度
- 你会意识到采样参数不只是可以拧来拧去的旋钮——它们是确定性计算和创造性输出之间的接口
核心要点
- Attention 为每个 token 算 Q、K、V;Q 去查 K 产生注意力权重,权重聚合 V 得到上下文感知的表示。KV Cache 存历史的 K、V,把每步从 O(n²) 变成 O(n)
- FFN(扩展 → 激活 → 压缩)引入非线性,据信存储了模型大部分事实性知识,约占 Transformer 参数的三分之二
- 多层堆叠创造抽象层次:浅层学语法,深层学推理。KV Cache 按层存储,缓存内存随
层数 × 序列长度 × KV 维度膨胀 - 解码阶段:最终隐藏向量过反嵌入矩阵 → logits → softmax → 概率 → 采样 → token。Temperature 控随机性,top-p 动态限候选池
- 采样是推理中唯一的非确定性来源。幻觉发生在概率分布给了错误 token 权重而采样器恰好选中它的时候——架构本身没有内置的事实核查