
从 Docker backup 到云服务器:Hermes Agent 迁移实录
一次 Agent 迁移真正困难的地方,往往不是把文件复制过去,而是确认它在新环境里还像原来一样“活着”。 昨天我把 Hermes Agent 从 Docker backup 文件迁移到了当前这台云服务器。表面上看,这只是一次恢复:把备份里的配置、会话、工作区和运行状态搬到新机器,然后把 gateway 拉起来。但真正做下来,我发现这类迁移和普通 Web 服务不太一样。一个 AI Agent 不是只有一个进程,它更像一套小型操作系统:有长期记忆,有 session history,有 cron,有浏览器,有子进程,有 delegation,有 MCP,还有 QQ 这样的消息入口。 所以迁移完成以后,我没有只看“服务是否启动”,而是做了一轮从底层路径到上层聊天入口的验收。最后的结论是:Hermes 主链路整体可用,但也暴露出两个不阻塞使用的问题,一个是 Mem0 依赖缺失,一个是 QQ approval button 的 dm / c2c 授权漂移。 先确认 Agent 站在正确的地面上迁移后的第一件事,是确认 runtime identity 和路径基线。对 Hermes...

看懂 Transformer Block:Attention、MLP、Residual 和 Norm 到底怎么配合
看懂 Transformer Block:Attention、MLP、Residual 和 Norm 到底怎么配合一句话:Transformer block 不是一团神秘公式,它每一层都在做四件朴素的事——attention 负责“看上下文”,MLP 负责“自己加工”,residual connection 负责“不丢原信息”,LayerNorm / RMSNorm 负责“不让数值失控”。 很多人在理解 Transformer 时,会先学到 self-attention、Q / K / V、position encoding、KV Cache、decoding 这些概念。它们相对容易建立直觉,因为都能和“模型如何读上下文、如何生成下一个 token”连起来。 但一旦进入 residual connection、LayerNorm、RMSNorm、Pre-Norm,难度会突然上升。原因不是这些概念本身多复杂,而是它们不直接回答“模型生成了什么”,而是在回答另一个更底层的问题:这么深的网络,为什么能稳定训练下去? 这篇文章就只讲一件事:一个 Trans...

从一次 Docker 迁移,看 Hermes Agent 里的 HOME 边界
一次看起来很普通的 VPS 到 Docker 迁移,最后变成了对 Agent 运行时边界的一次小型考古:HOME 到底是谁的 HOME? 最近我把 Hermes Agent 从 VPS 迁移到了 Docker。迁移本身并不复杂:数据目录挂载到容器里,gateway 跑起来,消息平台接上,日常使用基本恢复。真正让我停下来研究的,是 GitHub CLI。 我在容器里手动配置了 gh auth login,登录过程看起来也没问题,但回到 Hermes Agent 里使用工具时,GitHub CLI 却像是没有配置过一样。最开始我以为是 gh 的问题,或者是 token 没写进去。但查着查着,发现问题不在 GitHub CLI,而在 HOME。 一个很小但很烦的差异Docker 里的 Hermes 使用 HERMES_HOME 作为持久化数据根目录,比如: 1HERMES_HOME=/opt/data 这个目录里放配置、session、memory、skill、日志等 Hermes 自己的状态。为了避免工具把配置写到容器里不持久的 /root,Hermes 又给工具子进程准备了一个 ...

npm global 不应该被当成系统级包管理器
npm global 最大的问题,是它看起来像一个系统级包管理器,但实际上只是某个 Node 版本附带的“局部全局”。随着越来越多 AI CLI 工具通过 npm 分发,这个长期被忽视的问题会变得越来越明显。 过去这个问题不太显眼,是因为 npm global 主要用来安装前端开发工具,例如 TypeScript、ESLint、Prettier、Vite 或某些脚手架。即使这些工具随着 Node 版本切换而消失,通常也只是影响某个项目的开发环境,而且很多团队本来就会把它们放进项目的 devDependencies 里。 但现在情况变了。Claude Code、Gemini CLI、Codex CLI、各种 MCP server、agent framework、部署工具和 AI 应用脚手架,越来越多都选择通过 npm 发布。它们不再只是“项目开发依赖”,而是逐渐变成开发者每天使用的个人工作台入口。这个时候,如果继续把 npm global 当成长期稳定的全局 CLI 管理方式,问题就会被放大。 npm global 的“全局”是有条件的npm install -g 里的 globa...
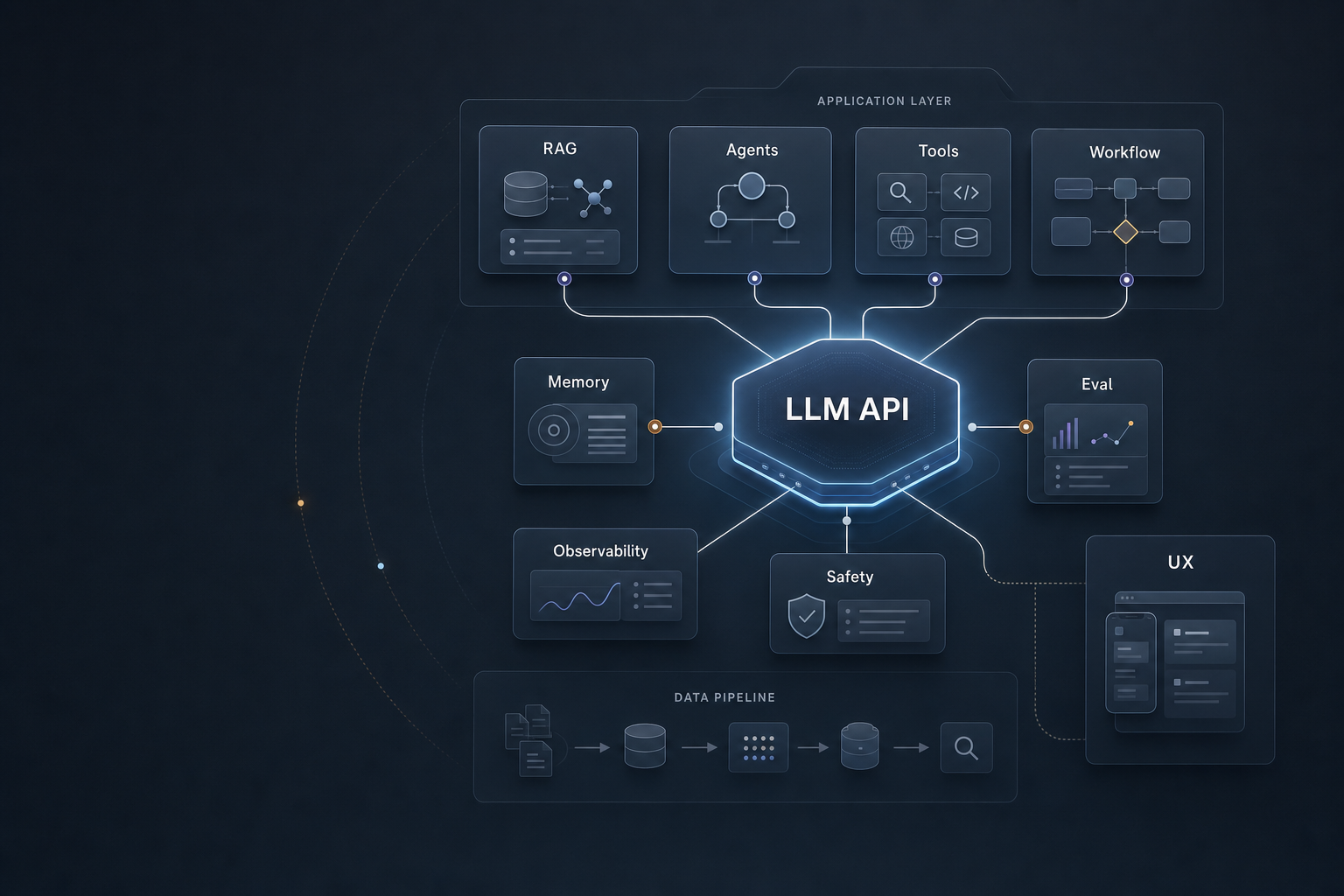
基于大模型 API 构建上层应用的知识地图
如果已经拿到了可以直接调用的大模型 API,那么真正值得投入的研究重点,就从“如何训练模型”切换成了“如何把模型变成可靠、可控、可评测、可持续迭代的应用系统”。 这篇文章整理一份面向 AI 应用层的知识地图。它的边界很明确:不讨论预训练、模型架构创新、GPU kernel、分布式训练这些底层问题,而是假设模型能力已经以 API 的形式交付给我们。我们要研究的是:如何在模型 API 之上,构建能解决真实问题的产品和系统。 从逻辑上看,应用层可以按“从输入到结果、从单次调用到持续运营”的顺序划分为七个领域:Context Engineering、Knowledge Grounding / RAG、Tool Use、Workflow / Agent、Evaluation、Observability、AI Product Design。 1. Context Engineering:让模型理解正确任务**Context Engineering 是所有大模型应用的第一层能力。**当我们不能修改模型参数时,能控制的就是上下文:任务说明、系统约束、用户输入、历史对话、外部资...
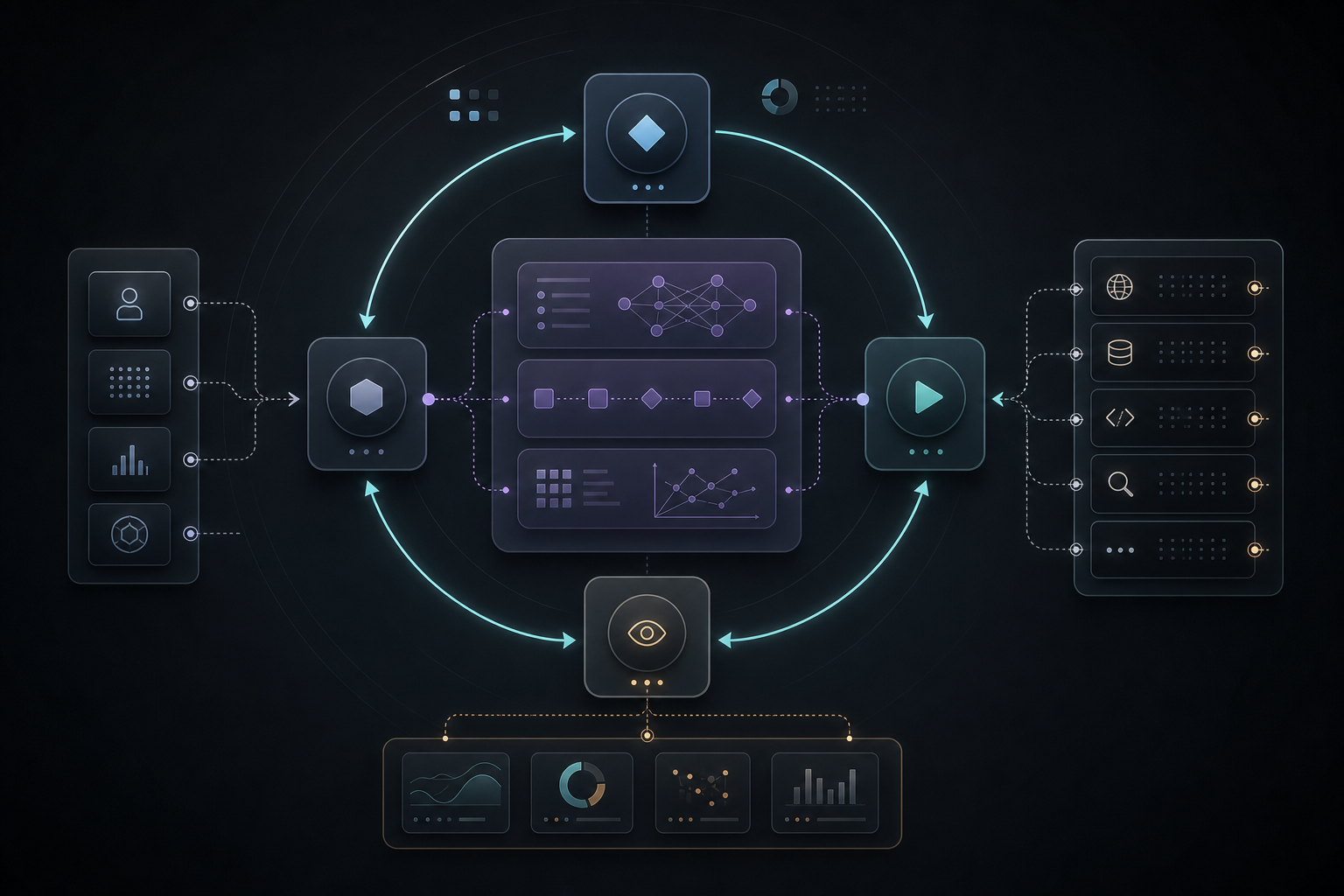
ReAct、CoT 与 Tool-Use:从想清楚到做清楚
ReAct、CoT 与 Tool-Use:从想清楚到做清楚一句话:CoT 解决”想清楚”,Tool-Use 解决”查清楚/做清楚”,ReAct 把两者编成闭环——推理指导行动,行动反馈推理。这是现代 AI Agent 的核心范式。 三个概念,一张关系图在 AI 工程的语境里,有三个高频概念总是纠缠在一起: Chain-of-Thought (CoT):让模型把推理过程一步步写出来 Tool-Use:让模型调用外部工具获取信息或执行操作 ReAct:把推理和行动交织成循环 它们不是三个并列的方案,而是递进的能力层次: 1纯 LLM(只靠记忆)→ 加 CoT(会想了)→ 加 Tool-Use(有手了)→ ReAct(脑手协调) 下面逐个讲透。 一、Chain-of-Thought:让模型把过程写出来核心思想让模型在给出最终答案前,把中间推理步骤显式地生成出来。就像老师要求学生”写解题过程,不能只写答案”。 直观对比不用 CoT: Q: 商店有 23 个苹果,卖了 15 个,又进货 8 个,现在有几个?A: 16 用 CoT: Q: 商店有 23 个苹果,卖了...

为什么"把聊天记录全塞进去"是 LLM 产品最常见的自杀行为
为什么”把聊天记录全塞进去”是 LLM 产品最常见的自杀行为 一句话结论:无限追加聊天历史不是”给模型的上下文越多越好”——它会在四个维度同时崩盘:硬天花板、成本爆炸、延迟倍增、信号被噪声淹没。成熟的 AI 产品用分层上下文架构替代全量追加。核心思路不是”给更多信息”,而是”给每个 token 更值钱的信息”。 四个同时发作的问题直觉很自然:用户聊了 30 轮,把每一轮都喂给模型,答案不就更有上下文了吗? 前十轮没问题。二十轮依然连贯。到四十轮左右,事情开始崩了: 回复变慢 成本悄然攀升 模型开始跑偏——重提二十分钟前的话题,跟刚说的矛盾,或者执着于某个过时信息 这不是偶发 bug,是系统性必然。原因有四层,层层叠加。 第一层:context window 是硬天花板GPT-4o 上限 128K token,Claude 200K,Gemini 2.5 Pro 1M。 数字看着大,但一个健谈用户在单次长会话里就能烧掉 100K。撞到天花板时你只有两个选择:从头截断(丢掉关键早期上下文),或者拒绝继续。两个都是烂体验。 第二层:Token 成本随每轮累积——沉默的杀手就...

推理模型如何"思考":一切都只是 Token
推理模型如何”思考”:一切都只是 Token一句话:推理模型没有做任何新事情。所谓的”先想再答”,就是把中间推理步骤写成 token 藏在后台不让用户看见。思考 token 和输出 token 由完全相同的前向传播产生——没有第二个模型,没有独立推理引擎,没有模式开关。一切都只是 token。 思考 Token 并不特殊首先要刻进脑子里的认知:思考 token 和输出 token 是完全相同的机制生成的。 都是同一个 autoregressive 过程——模型根据前面所有 token 预测下一个 token,把它塞回上下文,重复。前向传播是同一个,权重是同一套。不存在什么”推理副脑”、辅助模块、神经网络里的推理模式开关。 让思考 token 显得不同的唯一原因:谁看得见它们。标准聊天里,模型生成的每一个 token 都直接推给用户。推理模型里,模型先生成一段”思考”token——这些 token 在内部消费,用来影响后续 token 的预测——但不对最终输出暴露。只有思考块之后的 token 才送到用户眼前。 这意味着推理不是”在基座模型之上额外加的能力”。它是基座模型本来就有...

深入理解 LLM 函数调用:模型不会"决定"用工具
深入理解 LLM 函数调用:模型不会”决定”用工具一句话:函数调用不是模型内部”觉醒”的能力,而是推理层在 prompt 里塞了一套工具描述后,模型遵循协议输出的结构化 token。本质上是 prompt engineering 的延伸——只不过发生在 API 层而非用户输入层。 模型不会”觉得该用工具了”关于函数调用最大的误解,就是以为模型内部有个”我该调工具了”的判断机制。没有。模型就是一个 autoregressive token 生成器——给定前文,预测下一个 token。仅此而已。 函数调用是推理层启用的能力,需要两个显式条件同时满足: 请求里必须带 tools 参数——一个函数定义数组,每个函数包含名称、自然语言描述和 JSON Schema 参数规格。 tool_choice 参数必须允许调用。默认值是 "auto"——模型在它觉得合适时可能返回工具调用。你也可以设为 "none"(绝不下手)、"required"(必须下手),或锁定到某个具体函数。 当 tool_choice 为 "aut...
LLM 解码策略:temperature、采样与 beam search,到底在选什么
LLM 解码策略:temperature、采样与 beam search,到底在选什么一句话:所有解码策略本质上只做一件事——从模型输出的概率分布里挑一个 token。区别只在于你用什么规则去挑,以及你要确定性还是要多样性。 基础管道:Logits → Softmax → 概率分布模型最后一层输出的是 logits——词汇表里每个 token 对应一个实数,有正有负,范围不受约束。这还不是概率。 把它变成概率靠的是 softmax: 1P(i) = exp(logit_i) / Σ exp(logit_j) 做完这一步,你手里就有了一个合法概率分布:每个 token 一个概率,全加起来等于 1。后续的 temperature、top-K、top-P、greedy decoding、beam search——全是在这个分布上做文章。要么改分布的形状,要么换挑选的规则。 Temperature:一个旋钮控制”脑洞程度”Temperature 是调起来最简单的参数。它在 softmax 之前动刀,把每个 logit 除以 T: 1P(i) = exp(logit_i / T) /...