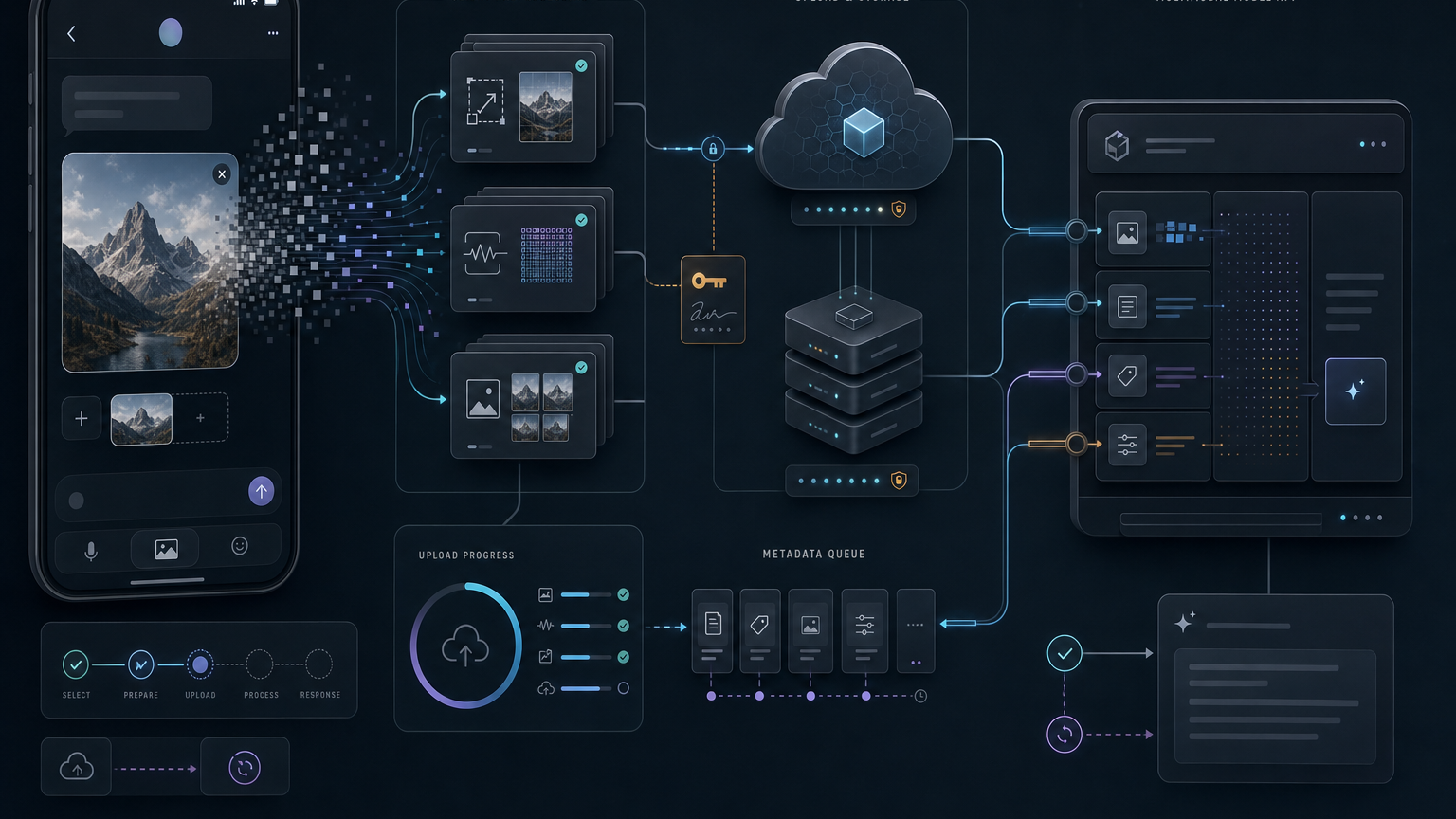
多模态 AI 聊天的图像上传:从字节流到用户体验
多模态 AI 聊天的图像上传:从字节流到用户体验一句话:给 AI 聊天加上图片上传,不是往聊天气泡里塞个 <img> 标签就完事了。它是一条从客户端预处理直通模型 API 的工程管线——上传架构、数据格式、预处理、UX 打磨,每层都有坑,踩过才知道。 上传架构:为什么图片不该经过你的服务器用户选了一张图,这个文件总得想办法到达模型 API。最天真的做法是把所有东西都过一遍你的后端:前端上传到你服务器,你服务器再转发给模型。五个用户的时候没问题,规模化之后直接崩——图片上传吃带宽、占请求线程,你的 API 服务器瞬间变成奢华版文件代理。 正确的姿势是直传 OSS。 后端只管签发临时凭证(STS token 或预签名 URL),前端拿着凭证直接上传到对象存储。流程是这样的: 用户选图 → 前端调后端拿上传 token 后端返回一个短期预签名 URL(有效期按分钟计,绝不按小时) 前端直传 OSS,拿到永久图片 URL 这个 URL 被塞进模型 API 请求——字节流从头到尾没经过你的服务器 后端保持轻量,客户端代码里也不暴露长期密钥。安全边界清晰:临时凭证、服务端签...

Transformer 到底怎么生成文本:逐层拆解
Transformer 到底怎么生成文本:逐层拆解一句话:Transformer 推理就四个阶段——Attention(信息路由)→ FFN(知识存储)→ 层层堆叠(抽象升级)→ 解码(从向量到词)。一旦你把这四个阶段吃透,KV Cache 为什么吃内存、长上下文为什么贵、temperature 到底在调什么、模型为什么会产生幻觉、speculative decoding 怎么加速——这些工程决策突然就变得自然而然了。 阶段一:Attention——让每个 token “看到”其他所有 token一个 token 刚进入 Transformer 层的时候,它对周围的 token 一无所知。Attention 就是来解决这个问题的。 每个 token 通过三个学出来的权重矩阵做投影,产出三个向量: Q(Query,查询): “我现在需要什么信息?”——当前 token 对历史的检索请求 K(Key,键): “我这里有什么信息可查。”——每个 token 的索引条目 V(Value,值): “这就是具体内容。”——被”关注”时实际传递出去的信息 当前 token 的 Q 去跟每...

从 Token 到 RAG:理解 AI Native 数据管道
从 Token 到 RAG:理解 AI Native 数据管道一句话:RAG 不是什么魔法,它只是在”大模型读不懂你的私有数据”这个问题上,搭了一条最务实的桥。这条桥由三块砖铺成——Token、Embedding、Vector Database。搞懂它们怎么连起来的、哪里会断,是每个做 AI 产品的工程师逃不掉的功课。 第一块砖:Token——模型看到的”文字”LLM 不读单词,也不读句子。它只认 token 序列。 输入是 token 序列,输出也是 token 序列。模型一辈子只干一件事:给定一串 token,猜下一个最可能的 token,然后把这个 token 拼到序列末尾,再猜下一个,循环往复。 一个 token 可能是一个完整单词(”apple”),也可能是子词碎片(”un” + “believ” + “able”),甚至只是单个字符——全看分词器怎么切。这是整个管道里最底层的粒度,一切从这里开始。 第二块砖:Embedding——把含义变成数字机器不认文字,只认数字。这是根本矛盾。 Embedding 模型做的事:把一段文本映射成一个固定长度的浮点数向量。Open...

低端设备上让 AI 原生应用"感觉快"的实战指南
低端设备上让 AI 原生应用”感觉快”的实战指南 一句话结论:在 150 美元、3GB 内存、弱信号的手机上,让应用”感觉快”靠的不是某个单一优化——而是把首次绘制拆成流水线、让虚拟列表根据设备内存动态适配、以及把图片加载做成优先级调度系统。这三件事做到位,白屏、卡顿、图片乱跳全消失。 场景还原做一个新闻资讯应用。首页是卡片滚动列表——标题、摘要、缩略图、日期。纸面上看着简单。 扔到一台 150 美元的 Android 手机上试试:3GB 内存,不稳定的 3G。白屏数秒。图片延迟加载挤得文字到处乱跳。滚动卡成幻灯片。应用”坏了”。 这不是假设——这是每个面向真实用户的工程师最终都要面对的场景。 第一条:首次绘制是流水线,不是单步事件最大的思维误区:认为”首页加载=请求数据→渲染→完事”。 在低端设备上,这个模式必然导致痛苦的白屏。实际上,首次绘制应该是一串渐进的里程碑: 1骨架屏 → 缓存读取 → 缓存渲染 → 网络合并 → 缓存写入 阶段一:骨架屏,0ms 出现应用壳就绪的那一刻,网络字节还没到。骨架屏立刻上屏。 这不是装饰——这是心理锚点。用户看到骨架,认知...
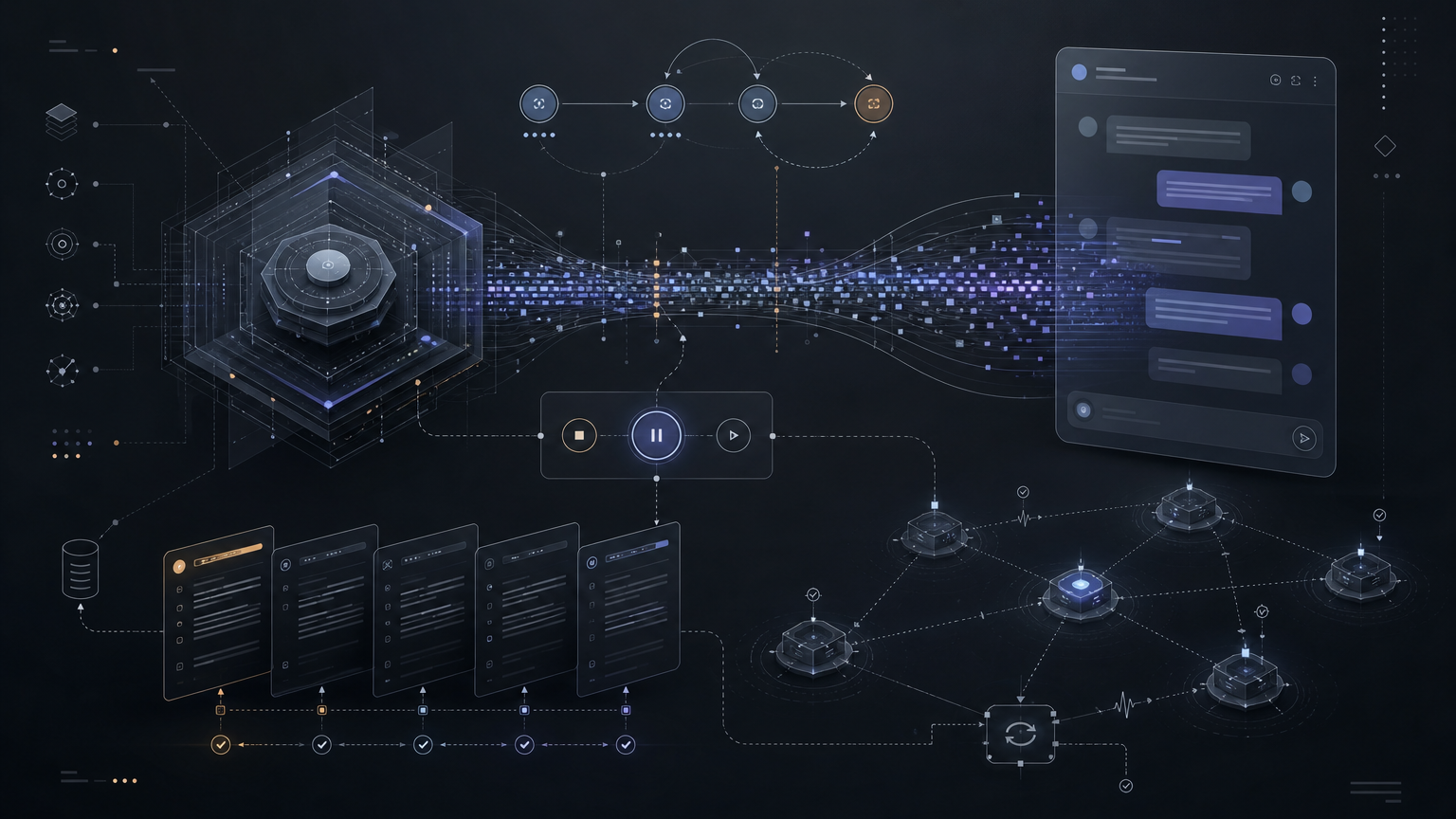
流式输出:AI 原生应用的默认交互范式
流式输出:AI 原生应用的默认交互范式 一句话结论:流式输出不是 UX 上的锦上添花——它是 LLM 应用的身份基石。但真正的难点从来不是”把 chunk 拼起来显示”,而是分布式状态一致性。搞不定这件事,你的停止按钮、刷新恢复、聊天持久化全是 bug。 本质:LLM 天生就该流式LLM 不是一次性产出整段文字。它 autoregressive 地工作:给定一串 token,预测下一个最可能的 token,追加到序列尾部,循环往复。 换句话说,模型本身就在增量地”吐”内容。那你把内容增量地交给用户,就是最自然的选择。 反过来,让用户盯着白屏等 5 秒、10 秒甚至 30 秒,等完整答复再一口气显示——这等于把”慢”暴露给用户,没有任何缓冲。用户会觉得应用坏了。 流式输出把体验翻转了:文字立刻开始出现,感知延迟大幅降低。更关键的是,它把”黑盒查询”变成了”实时协作”——用户可以边看边判断方向对不对,发现模型跑偏就立刻打断,省下浪费的 token。 这种可中断、可纠偏的交互模式,正是 AI 原生应用和传统 Web 应用的分水岭。 核心难点:三层状态机聊天 UI 看起来简单——接...
React/Next/Vercel + LeanCloud 快速搭建一个网站
引言如果你是一个前端开发者,想要独立上线一个网站,那么你大概会遇到下面这些问题: 前端如何部署? 域名和 SSL 证书如何配置? 后端使用什么框架? 后端如何部署? 使用什么数据库? 如何自动化部署? 能不能前后端放在同一个项目里,使用 JavaScript 全栈开发? 如果这些困难让你感到第一步很难迈出,那么可能你的很多想法都会止步于自己的脑海,而无法变成现实。中国互联网多年的经验已经证明了,快速的跑通全流程,然后再逐步迭代优化,才是效率最高的方案。 值得高兴的是,应该有不少人都曾有过这样的苦恼,所以现在市面上诞生了大量的解决方案。今天我要介绍的就是其中的一种。我的技术选型可能不是各方面都完美的最优解,但是它一定足够简单,简单到一位合格的前端工程师,可以在极短的时间就能跑通全流程。 数据库部分对于一名前端工程师来说,数据库部分可能会比较棘手。所以我先说一说这部分的问题如何解决。 LeanCloud 是一家提供 serverless 云服务的公司。如果你有折腾博客的经历,那么大概会知道 Valine 这个评论系统,它就是基于 LeanCloud 实现的存储功能。 可以通过具体...
完美的代码无法拯救你的公司
原文链接:The perfect codebase won’t save your company 软件工程是一个有技术门槛的行业。好的软件工程师总是事半功倍,他们可以完成别人甚至都不知道如何开始的工作。但是为什么几乎找不到那种公司,是由技术大牛带着一群人,开开心心地写着完美的代码呢?这是不是一场阴谋,是那些不懂技术的管理和市场人员,想要压制聪明的技术人员? Software engineering clearly takes skill. A good software engineer is a force multiplier, and can accomplish tasks that other engineers wouldn’t even know how to start. So why are there little-to-no tech companies with perfect codebases that are a delight to work in led by rock star engineers? Is there a c...
我的软路由折腾心得
引言基于多年软路由折腾经验总结出的个人最佳实践。 设备软路由设备的选择我推荐满足以下几个需求: 最少两个网口:单网口只能做旁路有,配置难度会更大一些 x86 架构:固件最好找,奇怪问题更少 带风扇:主动散热效果远好于被动散热,对网络稳定性有明显提升 我目前使用的是零刻 EQ12,大家可以根据自己的财力去电商平台选购。这可能会是一个比较花时间的过程。 固件软路由固件我推荐 iStoreOS,主要因为以下几个原因: 有容易找到的官网:https://www.istoreos.com,可以方便地查阅文档、下载固件 有专门的团队长期维护,可以在后台管理页面操作固件更新 配置相对简单 想要内网穿透可以直接使用官方的 ddnsto,配置简单、价格便宜 刷机有了设备和固件,接下来就需要把固件写入设备。 准备好的固件必须是 img 格式的,如果是 img.gz 则需要解压,而 bin 格式则是升级包,不适合刷机。 刷机有很多的途径,核心思想都是把 img 镜像写入设备的启动介质上。启动介质可以是硬盘,也可以是 U 盘、TF 卡。针对 x86 设备,有以下一些方式: physdiskwr...
我心目中合格的 NAS
引言我的第一台 NAS 是群晖 DS218+,花了我 2650。买第一台 NAS 的时候,把这个东西想的过于简单了,以为只要买回来,下载安装 APP 就可以愉快的玩耍了。当时不知道什么是 PT、不知道什么是流媒体服务器,不知道什么是 SMB 共享,下载了一堆群晖自己的 APP,体验了几天之后就彻底失望了,感觉不知道自己买了个什么残次品,也搞不懂为什么网上都说买群晖省心。 我的第二台 NAS 是绿联 DH2600,花了我 2198。2 SATA + 2 M.2 盘位,N5105 处理器,4GB 内存,支持 docker。当初买这台 NAS 的时候几乎纯粹就是奔着硬件去的,看着这个配置,感觉系统就是一坨屎我也能接受。 绿联用了有快两年的时间,系统一直算不上好用,但是没有群晖那种用不下去的感觉。直到今年绿联开始了一系列让人看不懂的操作: 宣布老系统更新放缓,全力开发新系统 宣布新系统不向前兼容,老系统升级需要格盘 618 新品发布,新系统 bug 层出不穷,引发退货潮继而绿联暂时下架了所有新品 一番操作下来,让我对这个品牌的信任感大大降低,有了一些想要逃离的想法,于是开始思考:什么...
64 位 Ubuntu 部署饥荒独立服务器
记录在 64 位 ubuntu server 上手动部署饥荒独立服务器的流程。 关键点 安装 steamcmd 安装 Don’t Starve Together Dedicated Server 准备一个存档 给存档添加 cluster_token.txt 饥荒独立服务器,启动! 【服务器】安装 steamcmdsteam 有官方的文档,告诉你应该如何安装 steamcmd:下载 SteamCMD ,官方强调了不要使用 root 用户来操作,其中核心的部分如下: 1234sudo add-apt-repository multiversesudo dpkg --add-architecture i386sudo apt updatesudo apt install lib32gcc-s1 steamcmd 安装成功的标志,是可以在任何目录下直接用 steamcmd 命令。很多教程会把这一步弄的十分麻烦,其实完全没有必要。 【服务器】安装 Don’t Starve Together Dedicated Server有了 steamcmd 以后,安装 Don’t Starve T...