基于大模型 API 构建上层应用的知识地图
如果已经拿到了可以直接调用的大模型 API,那么真正值得投入的研究重点,就从“如何训练模型”切换成了“如何把模型变成可靠、可控、可评测、可持续迭代的应用系统”。
这篇文章整理一份面向 AI 应用层的知识地图。它的边界很明确:不讨论预训练、模型架构创新、GPU kernel、分布式训练这些底层问题,而是假设模型能力已经以 API 的形式交付给我们。我们要研究的是:如何在模型 API 之上,构建能解决真实问题的产品和系统。
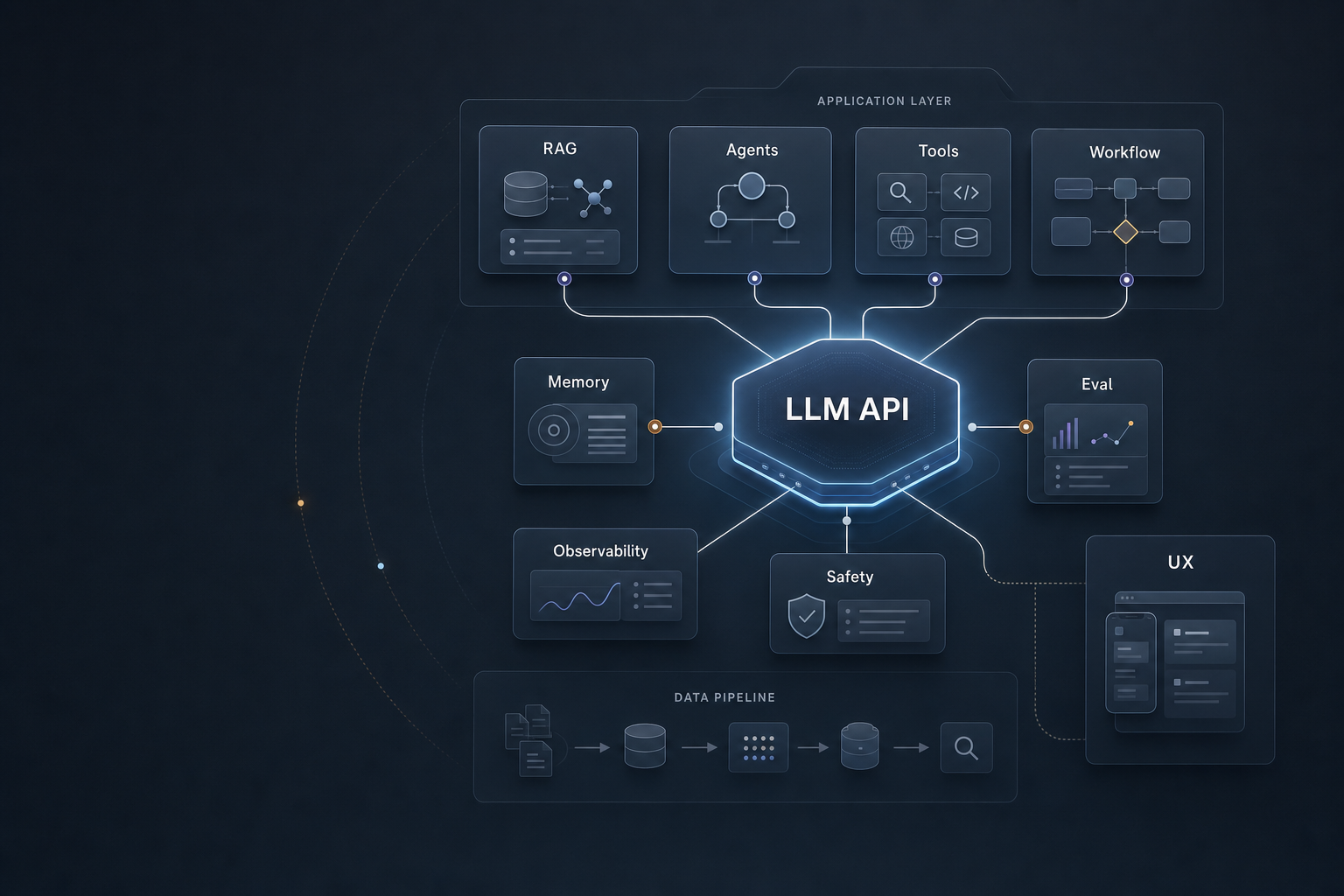
从逻辑上看,应用层可以按“从输入到结果、从单次调用到持续运营”的顺序划分为七个领域:Context Engineering、Knowledge Grounding / RAG、Tool Use、Workflow / Agent、Evaluation、Observability、AI Product Design。
1. Context Engineering:让模型理解正确任务
**Context Engineering 是所有大模型应用的第一层能力。**当我们不能修改模型参数时,能控制的就是上下文:任务说明、系统约束、用户输入、历史对话、外部资料、工具结果和输出格式。
这一层要研究的不是简单的“写 prompt”,而是如何组织整个上下文窗口。包括 system prompt 如何定义角色与边界,developer message 如何表达稳定规则,few-shot examples 如何降低输出波动,多轮对话如何保留状态,长上下文如何压缩,以及如何通过 structured output 让模型返回可被程序消费的 JSON、表格或 DSL。
在应用实践中,很多失败不是模型没有能力,而是上下文没有把目标、约束和判断标准说清楚。因此这一层的核心问题是:如何让模型在有限上下文里获得完成任务所需的最小充分信息。
2. Knowledge Grounding / RAG:让回答建立在外部事实上
当应用涉及企业文档、行业知识、产品手册、代码库、政策法规或实时信息时,仅靠模型内部知识是不够的。这时需要 RAG,也就是 Retrieval-Augmented Generation。
RAG 的完整链路包括文档解析、chunking、embedding、索引、query rewrite、retrieval、reranking、context compression、answer generation 和 citation。它的目标不是“把资料塞给模型”,而是让模型在回答前拿到与问题最相关、最可信、最可追溯的知识证据。
这一领域可以继续拆成几个重点:文档解析负责把 PDF、网页、表格、图片 OCR 转成结构化文本;chunking 决定知识被切成什么粒度;embedding 和 hybrid search 决定召回质量;reranker 决定排序质量;citation 决定用户能否追溯来源;RAG evaluation 决定系统是否真的检索到了正确依据。
对于知识密集型应用,RAG 是降低幻觉、连接私有知识和形成可解释答案的核心基础设施。
3. Tool Use / Function Calling:让模型从“回答”走向“行动”
聊天应用只需要模型生成文本,但真正的业务应用通常需要模型调用工具:查数据库、调接口、搜索网页、发邮件、创建工单、生成文件、操作浏览器或执行代码。
Tool Use 的核心是 function calling。我们需要为每个工具设计清晰的 schema,让模型知道工具能做什么、参数是什么、什么时候该调用、调用失败后如何恢复,以及工具结果如何再进入上下文。
这一层尤其需要关注安全边界。不是所有动作都应该由模型自动执行。涉及转账、删除、发送、发布、改配置等高风险操作时,需要 permission control、sandbox、human-in-the-loop 和 audit log。模型可以提出动作,但关键动作要有确认、回滚和审计。
这一领域的核心问题是:如何让模型可靠地选择工具、填写参数、处理结果,并在权限边界内完成真实任务。
4. Workflow / Agent:把多步骤任务组织起来
如果一个任务可以通过一次模型调用完成,它只是普通 LLM application;如果任务需要拆解、执行、观察、修正和继续推进,就进入 Workflow / Agent 领域。
这里要区分 workflow 和 agent。Workflow 更偏确定性编排,例如固定的“读取需求 → 检索资料 → 生成草稿 → 人工确认 → 发布”流程。Agent 更偏动态决策,例如模型根据当前状态决定下一步调用哪个工具、是否需要补充信息、是否已经完成任务。
在真实应用里,推荐优先采用 确定性 workflow + 局部 LLM 决策,而不是一开始就追求完全自主 Agent。因为固定流程更容易测试、解释和控制;模型只在需要语义判断、生成、规划的节点发挥作用。
这一领域需要研究 state machine、task decomposition、planner-executor、memory、retry、rollback、task queue、multi-agent collaboration 和 human approval。它的核心问题是:如何把模型调用、工具调用和业务规则编排成稳定的多步骤系统。
5. Evaluation:知道系统到底好不好
没有 Evaluation,大模型应用只能靠感觉迭代。Prompt 改一点、模型版本换一下、知识库更新一下,都可能导致输出质量变化。因此应用层研究必须把评测放在核心位置。
Evaluation 至少包括四类:输入理解是否正确,检索内容是否正确,工具调用是否正确,最终输出是否满足用户目标。对于 RAG,要评测 context recall、context precision、faithfulness 和 answer relevance;对于 Tool Use,要评测工具选择、参数填充、调用顺序和失败恢复;对于 Agent,要评测任务完成率、步骤成本、循环次数和人工介入率。
常见方法包括 golden dataset、prompt regression test、LLM-as-a-Judge、human evaluation、A/B test 和线上反馈采集。这里最重要的是建立一套稳定样本,让每次系统改动都能回归验证。
**Evaluation 是从 demo 走向产品的分水岭。**没有评测,就无法判断系统是在进步还是退化。
6. Observability:让系统可追踪、可诊断、可优化
Evaluation 解决“好不好”,Observability 解决“为什么”。一个成熟的大模型应用需要记录每次请求的 trace:用户输入、prompt 版本、模型版本、检索结果、工具调用、token 消耗、延迟、错误、最终输出和用户反馈。
这一层包括日志、trace、metrics、cost tracking、latency monitoring、prompt versioning、model routing、retrieval analytics 和 error analytics。它帮助我们回答很多运营问题:哪个 prompt 最容易失败?哪个知识库命中率最低?哪个工具调用最慢?哪类用户问题成本最高?模型升级后质量是否下降?
对商业应用来说,成本也是架构问题。上下文越长、模型越强、调用次数越多,成本就越高。Observability 可以帮助我们决定是否需要缓存、压缩上下文、改用小模型、做模型路由或减少不必要的工具调用。
这一层的核心问题是:如何让每一次模型行为都可追踪、可解释、可复盘、可优化。
7. AI Product Design:让用户真正愿意使用
最后一层是 AI Product Design。AI 应用不是把聊天框放到产品里,而是重新设计用户完成任务的路径。
这一层要研究 AI UX、trust design、error recovery、feedback loop、personalization 和 business workflow integration。用户需要知道 AI 能做什么、不能做什么、依据是什么、哪里不确定、如何修改结果、何时需要确认。对于高风险场景,产品要把模型的不确定性显式展示出来,而不是伪装成绝对正确。
好的 AI 产品通常不是让用户写复杂 prompt,而是通过界面、表单、模板、上下文自动收集和工作流,把用户输入成本降到最低。用户看到的可能只是一个按钮或一个 Copilot,但背后是 context、RAG、tool use、workflow、evaluation 和 observability 的组合。
这一层的核心问题是:如何把模型能力嵌入真实业务流程,让用户可理解、可信任、可控制地完成任务。
一张完整的应用层知识地图
1 | AI Application Layer |
学习顺序建议
如果用于后续探索与学习,可以按下面的顺序推进:先学 Context Engineering,因为它是所有模型 API 应用的入口;再学 RAG,解决知识和事实问题;然后学 Tool Use,让模型具备行动能力;再进入 Workflow / Agent,处理复杂多步骤任务;最后补上 Evaluation 和 Observability,把系统从 demo 推向可持续迭代的产品。
也就是说,一条更实用的主线是:
1 | Context Engineering |
这条线背后的判断是:先保证模型“理解对”,再保证它“依据对”,然后让它“行动对”,接着让多步骤任务“流程对”,最后用评测和观测保证系统“长期变好”。
结语
基于大模型 API 构建上层应用,本质上是一门新的应用系统工程。它既不是传统后端开发的简单延伸,也不是模型研究的下游附属品。它关注的是如何把不稳定、概率性的模型能力,包装成稳定、可控、可信任的用户体验。
因此,我后续的学习重点会放在这条主线上:Context Engineering + RAG + Tool Use + Workflow / Agent + Evaluation / Observability。如果说基础模型决定了能力上限,那么应用层研究决定了这些能力能否真正进入现实世界。